原文地址:https://nixintel.info/osint/how-to-find-timestamps-for-verification/
文章原名:How To Find Timestamps For Verification
作者: Nixintel
对于网络侦探(internet investigator)来说,能准确证明数据是什么时候发布在互联网上属于一种核心技能。如果你想能证实某个视频何时第一次上传,某个账户何时创建,或者是某个网站何时进行了编辑更改,那你就需要尽可能的精确确定时间。
这似乎很简单,因为当一篇文章被发布时或一张照片被上传时,发布时间和日期将被展示在网站页面上,但是这种可见的时间信息通常达不到详细分析或验证工作所需的精度。幸好网页源代码中通常隐藏着额外的时间戳数据,它们并不直接显示在浏览器中。通过获取这些隐藏的信息来创建非常精确的时间表,准确的证明或反驳某些事情发生的时间,这将显著的提升调查的准确度。
每个平台都采取独有的方式进行时间信息的存储。这意味着要经过一些试错才能发现不同平台的时间存储方式,但大体上有两种方法进行这些数据的获取。一种是查找嵌入在网页源代码中的信息,另一种是查找网站数据库向浏览器发送的JSON内容中的信息。第一种方式比第二种稍微简单一些,所以让我们从一个查找youtube直播的详细时间戳为例进行说明。
YouTube 直播时间信息 YouTube可以很好的展示浏览器中展示的少量时间信息与隐藏在网页源代码中的详细时间信息的差异。
这有一场我们在上周也就是2022年1月27日的直播:OSINT Curious livestream video 。视频下方展示了首次直播的状态信息。
但我们并不能知道直播是在那天的什么时候开始的。YouTube只为我们提供了日期,没有准确的时间,所以我们需要通过挖掘页面源代码来寻找更多明确的信息。
想要查看页面源代码,你需要右键单击浏览器,然后单击“查看源代码”或“查看页面源代码”。你会看到这样的东西:
它们是你从Youtube获取到的原始HTML和javascript,浏览器会将它们翻译成你所看到的页面。你的浏览器并不是将获取到的所有数据呈现在页面上,这些未使用的数据我们依旧可以访问。通过快捷键Ctrl+F 调出搜索栏,搜索类似“uploaded ,time , date , published , created ” 等关键字通常可以找到额外的时间相关信息。
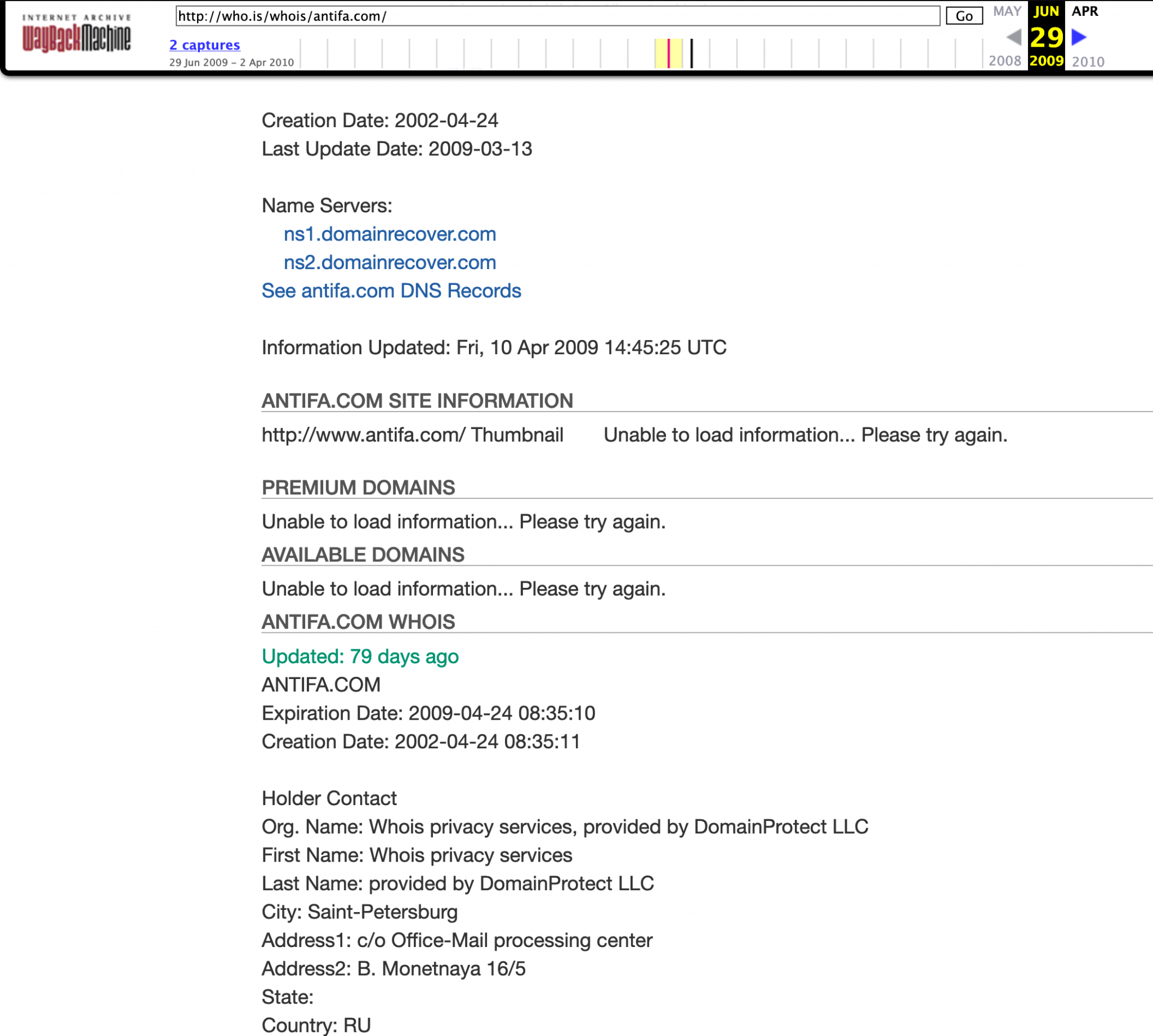
果然,通过搜索”published “我们发现了一些有用的信息。
我对代码进行了美化以方便阅读:
1 2 3 4 5 6 7 8 <meta itemprop="interactionCount" content="441"> <meta itemprop="datePublished" content="2022-01-28"> <meta itemprop="uploadDate" content="2022-01-28"> <meta itemprop="genre" content="Entertainment"> <span itemprop="publication" itemscope itemtype="http://schema.org/BroadcastEvent"><meta itemprop="isLiveBroadcast" content="True"> <meta itemprop="startDate" content="2022-01-27T19:59:36+00:00"> <meta itemprop="endDate" content="2022-01-27T20:35:05+00:00"> </span></div>
标签meta itemprop中包含了比之前我们看到的更加精确的时间信息。startDate标签说明了直播在1月27日19:59:36(UTC时间)开始,endDate标签说明了直播在当天20:35:05结束。注意,标签uploadDate说明了并不是在直播结束立刻进行了上传,这可能是由于一些延迟造成的。但仍然能从给出的开始与结束时间精确的确定直播时段。
如果你想知道这种技巧在现实世界调查中的使用,你可以看看Brecht Castel是如何通过直播的时间信息 去确定近期一次street demonstration的时间线。
推特账户创建时间信息 挖掘时间戳数据的第二种技巧涉及到对网站数据库所传递的信息进行捕获。当你通过你的浏览器访问网站时,你将向网站服务器发送请求以获取存储在站点数据库内的数据。服务器将响应你的请求,返回数据库中匹配的信息。通常情况下,数据库以JSON格式传递数据,浏览器将响应的JSON数据渲染成你所见的的网页。
通过使用浏览器的开发者模式 ,就能看到所有这些请求和响应的内容。这通常包含了很多在页面源代码中并不总是可用的有趣额外信息。让我们看看这些内容在推特账户创建时间戳上是怎样的。
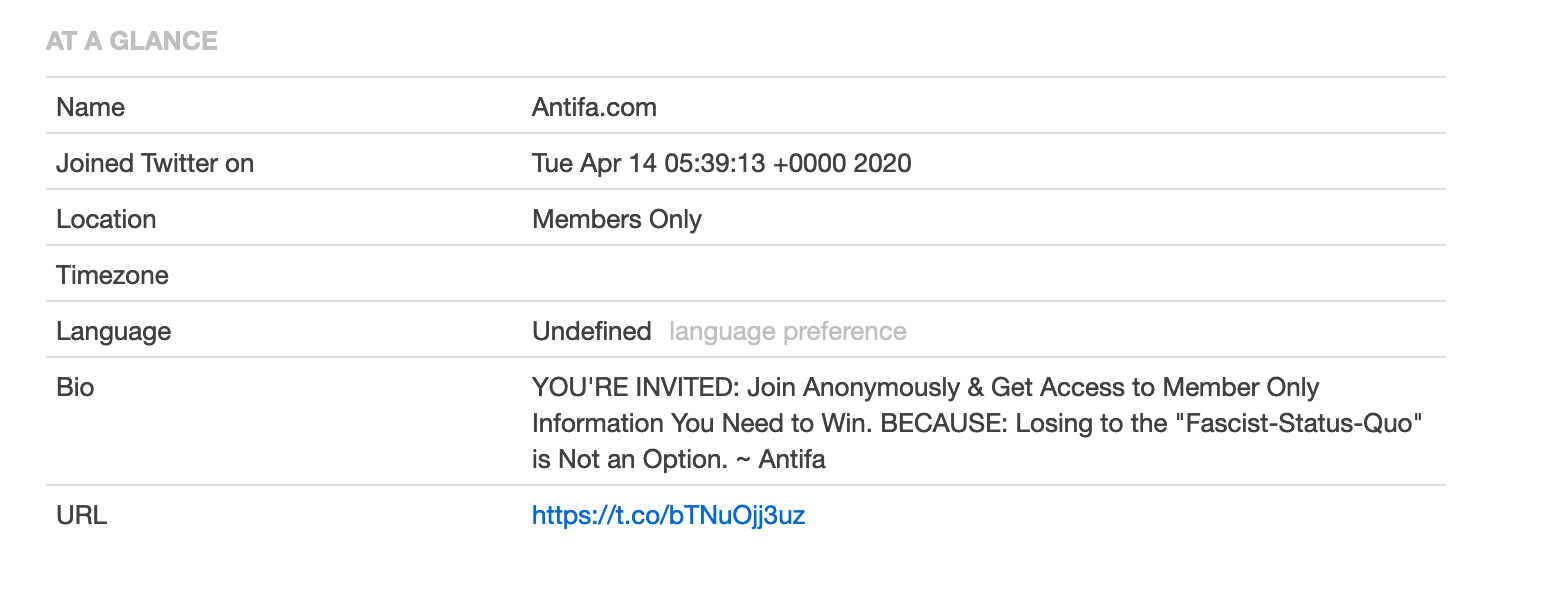
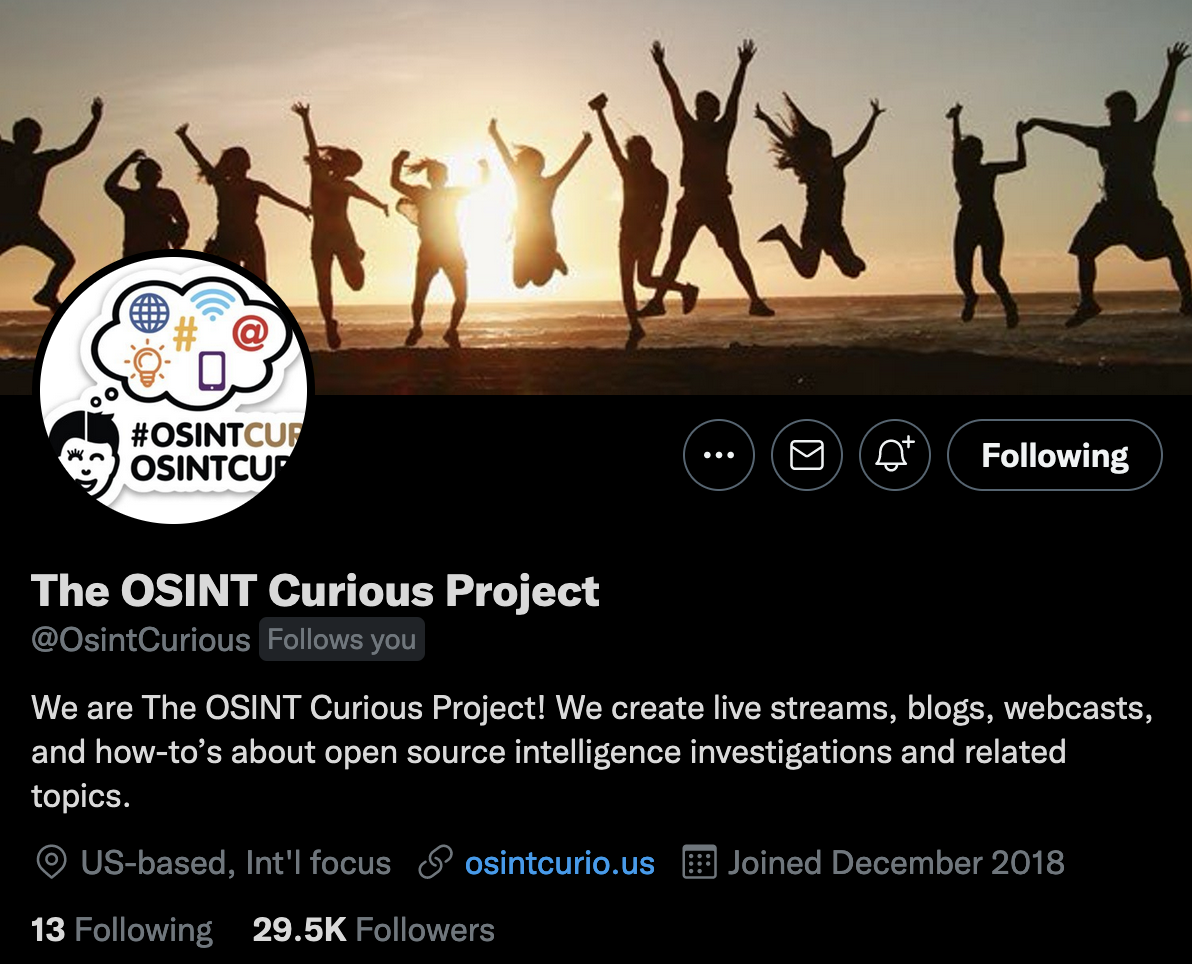
The OSINT Curious Project的推特账户是什么时候创建的? 很明显答案是2018年12月,就在个人资料页上。对于一般推特用户来说,这就足够了。但如果你正在调查一个魔怔人账户,或者是一系列由外国政府所设立用于传播虚假信息的账户,这样的信息并不精确。
当你只有按年、月记的账户创建时间时,你很难精确的说明一个账户何时创建,或者证明一系列可疑的账户恰好在同一时间内创建。
通过检索网站的请求与响应信息,我们可以找到许多关于账户何时创建的特殊信息。首先按F12进入浏览器的开发者模式。在这里我使用了Firefox,不过在Chrome上的操作流程是一样的。
1 2 1. 按下**Ctrl + R**重载页面 2. 点击**Network** 选项卡,你就能看到:
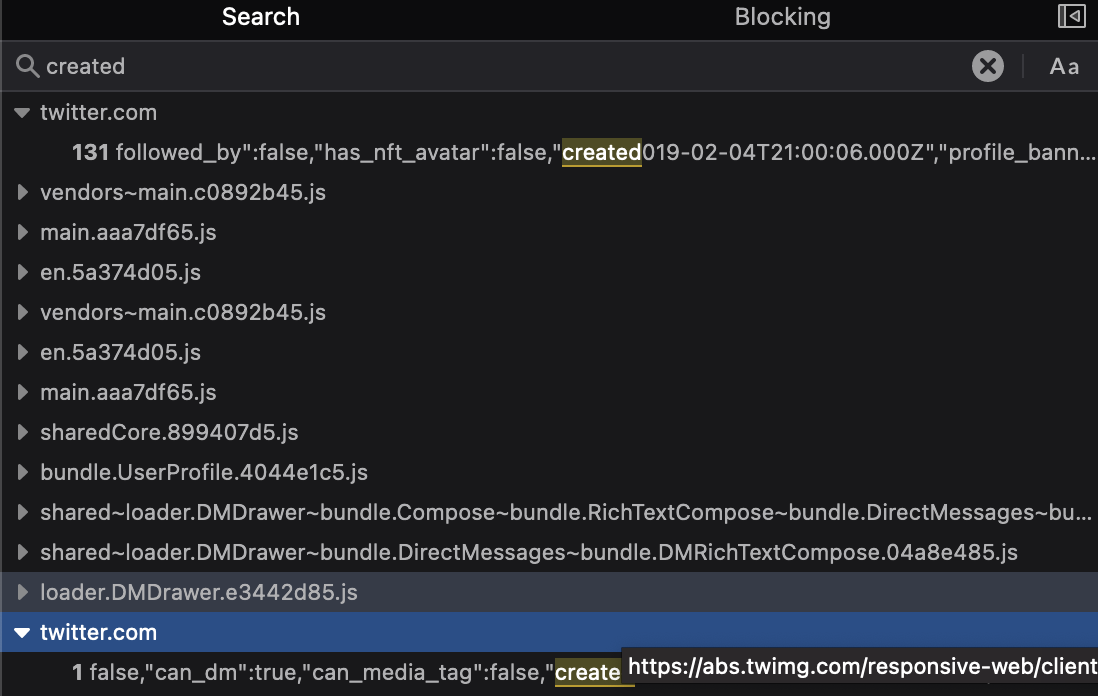
这里你可以看到你的浏览器与推特服务器之间所有的请求与响应。这里有非常多的信息,人工筛选比较困难。幸好我们可以像之前在处理Youtube页面源代码时一样,通过像time , posted , published , created 这类关键字进行过滤。点击放大镜图标(在“initiator”列的正上方)将调出搜索栏,输入关键字进行搜索。
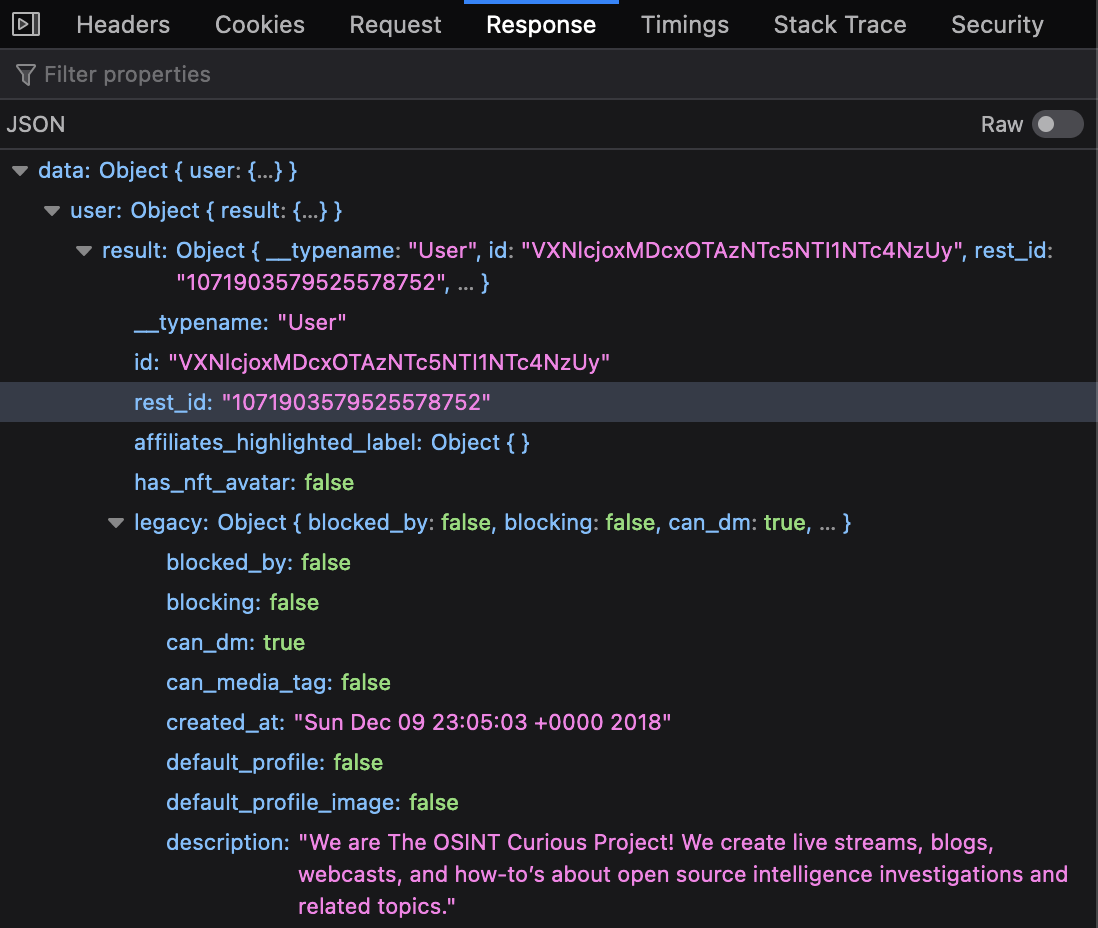
并不是所有信息都是相关的,但在”twitter.com”下找到的条目都指向来自推特的JSON数据,这其中包含的有关推特账户个人资料的信息可比在网页中可见的信息多得多。注意,因为推特在同一页面上展示了很多其他人的个人资料(“你可能喜欢…”),你将获得不止一个账户的信息。
点击其中一条结果将打开如下所示的用于显示响应的面板。取消”raw”选项来让原始数据以可读格式显示,就像下图所示:
created_at 字段显示了账户创建时的完整时间戳。我们之前仅知道该账户在2018年12月创建,但现在能准确的知道精确到秒的创建时间,这对调查来说非常有用。
Instagram 帖子和评论的时间信息 一旦你熟悉了如何在网页源代码或服务器响应中进行检索,那么想获取其他类型的数据也很容易。Instagram是出了名的难搞,但还是能找到一些有用的数据片段。调查员在Instagram上遇到的第一个挑战就是随着时间而变得模糊的时间戳信息。最近的帖子时间显示的很具体(例如“9小时前”),但随着时间的推移,帖子发布的时间将仅显示日期而没有具体时间,评论的时间戳信息仅以周为单位。对于Instagram用户来说当然不成问题,但对于想要精确的复现事件何时发生的调查员来说,问题很大。
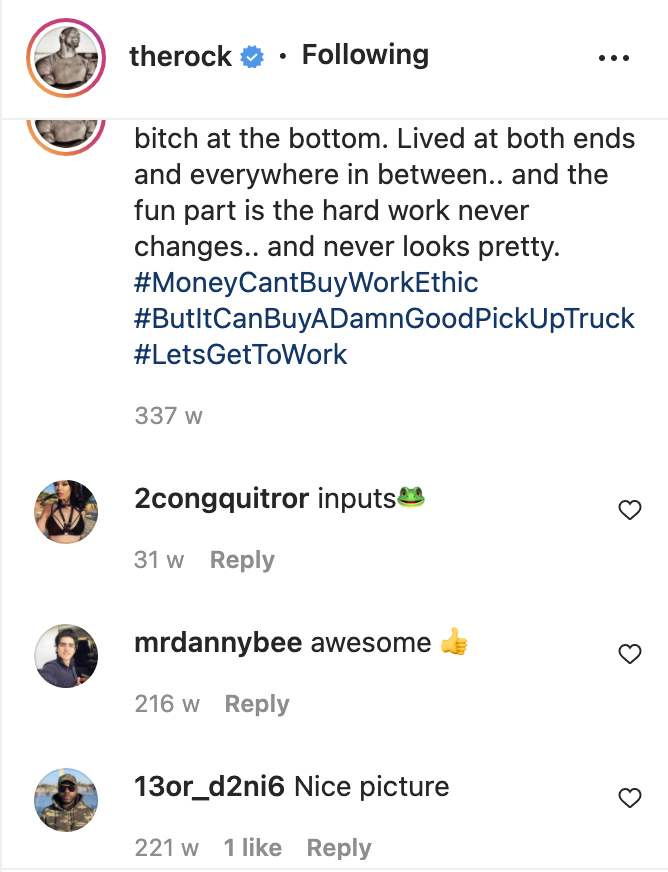
所幸,Instagram的服务器响应中也隐藏了一些有趣的信息供我们所用。让我们看看能从Rock 的账户中找出什么吧。
在我写这篇文章时(2022年2月6日 星期日),Rock最近发布的文章展示了他在健身房锻炼。我可以看到它是在9小时前发布的。
现在看起来没什么问题,但如果我想对数月甚至数年前发布的内容分析时会发生什么?这篇2015年发布的内容 展示了信息是如何随着时间推移变得模糊的。虽然它仍有时间戳(2015年8月19日),但只有日期没有具体时间。评论的信息更加模糊,它们甚至只显示了在多少周之前发布的,这种信息的用处不大,没法获得具体的发布时间。
不过一定会有一些有用的数据。除非它有额外的时间戳信息可供参考,不然Instagram 怎么能告诉我评论是在 216 周前发表的。如果我们能找到这些额外信息,我们应该能够获取到更准确的时间戳数据。
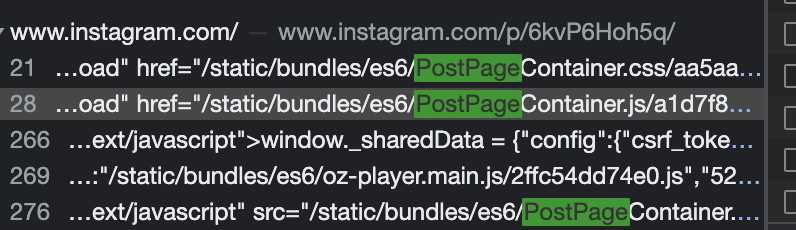
为了查找特定 Instagram 帖子的时间戳信息,要像 上面的Twitter 示例一样在开发人员模式下打开页面。通过搜索PostPage条目将找到一些有用的JSON数据,包含了有关发布内容的额外信息,其中还有时间戳数据。可能会找到很多与PostPage相匹配的信息,你所需要的信息将列在正在研究的贴子的主URL下。当URL是https://www.instagram.com/p/6kvP6Hoh5q/ 时,下图就是相关信息所在的位置。根据检索的结果可知,“PostPage”信息可以在响应内容的第 21、28、266、269 和 276 行找到
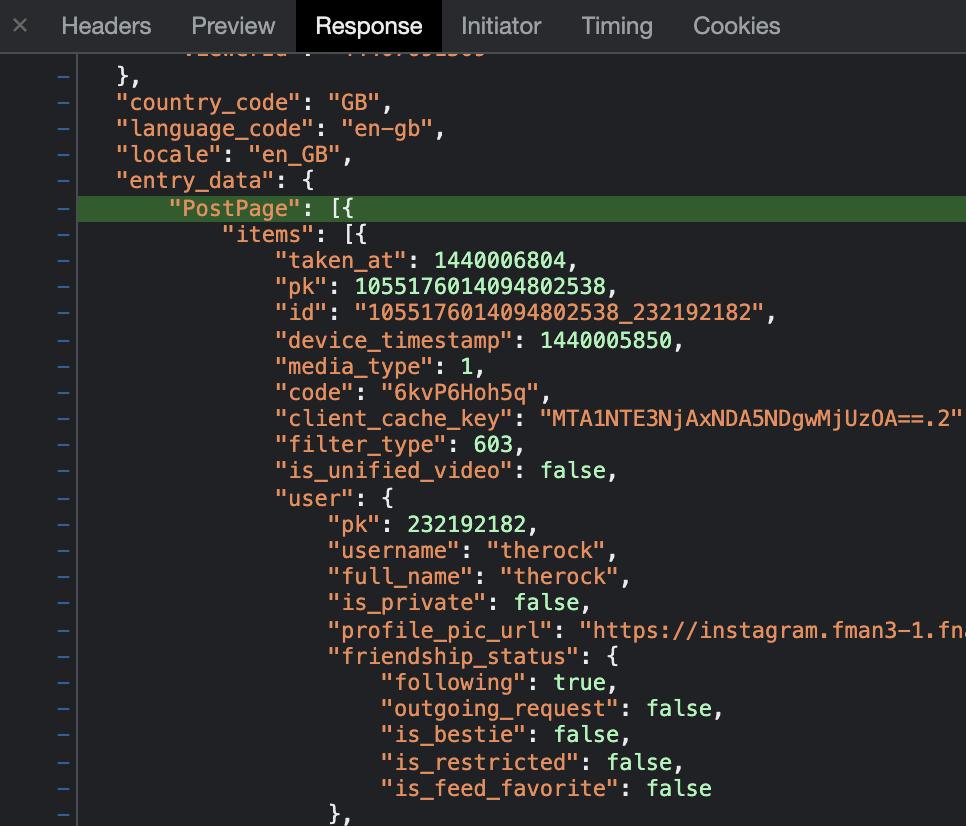
在第266行可以找到:
taken_at条目存储了UNIX格式的时间戳。使用UNIX timestamp convertor 我们可知1440006804即为2015年8月19日星期三 17:53:44。这可比单纯的日期精确多了。
你可能已经注意到了还有一个被叫做device_timestamp的UNIX时间戳。在本例中,它记录的时间是同一天的17:37:30,大约比taken_at字段存储的时间早了16分钟,这是怎么回事?在对此的研究中,我注意到device_timestamp字段记录的时间总是在taken_at字段之前。目前对此我最好的解释是device_timestamp基于图像或视频在设备上实际创建的时间,而taken_at字段反映了实际的上传时间。我需要做一些额外的研究来验证我的假设,但目前来说这是个合理的推断。
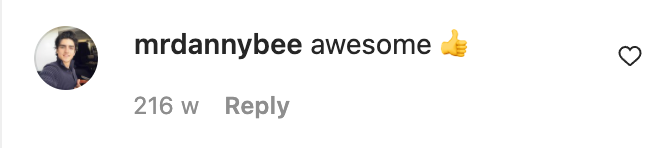
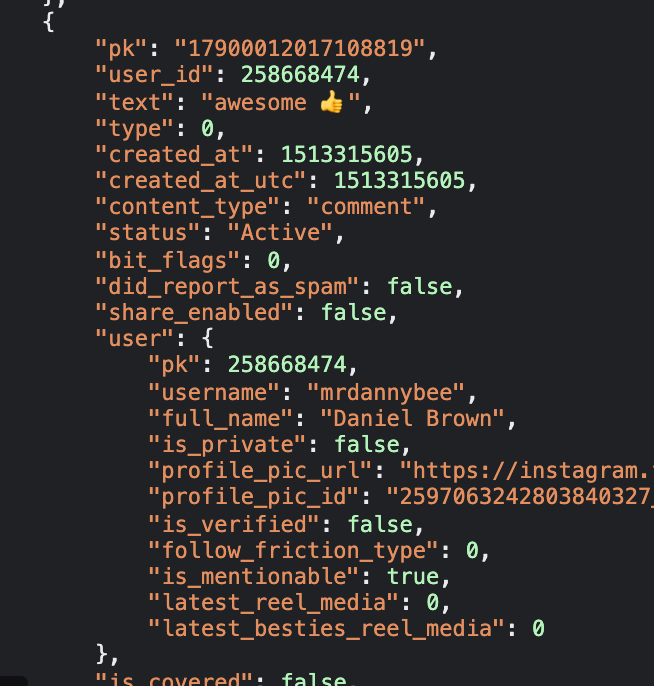
获取评论时间戳信息的流程也是相同的。Instagram 显示 mrdannybee 对 Rock 帖子的评论是在 216 周前发布的,但在回复中搜索“mrdannybee”会找到与他评论相关的 JSON数据,其中包含更具体的时间戳:
果然 1513315605 指的是 2017 年 12 月 15 日星期五 05:26:45 UTC,也就是 在216 周前。可以使用DateTimeGo 进行核查,它将为你计算出 x 周或数月前的实际日期。
本文只是对从网站内容中检索更详细的信息的几种技术的简要概述,但一旦你学会了如何通过这种方式寻找额外的数据,它就为寻找有用的数据提供了更多的机会。
如果你觉得这篇指南很有用,那你还可能很喜欢我之前关于从网站上发布的图片中提取时间戳(extracting timestamps from images posted on websites )的文章。
 }
}